简介
分布式系统中,消息队列是很重要的一个部分,广泛使用在异构系统间通信、服务内部异步化、广播和通知机制等。
rabbitMQ和kafka是用的比较多的消息队列系统,在这里进行一个比较的总结,对于系统设计、后续项目选型有一定的意义。
问题
经常听到以下一些观点:
- kafka比rabbitMQ性能更高,支持更高的吞吐量。
- rabbitMQ支持了AMQP协议,有确认机制,比kafka可用性更高。
- rabitMQ是推(push)的模型,kafka是拉(pull)的模型,rabbitMQ实时性更高;
为什么?知道结论固然重要,但更需要深入探究原理、探究其设计思路。
路由
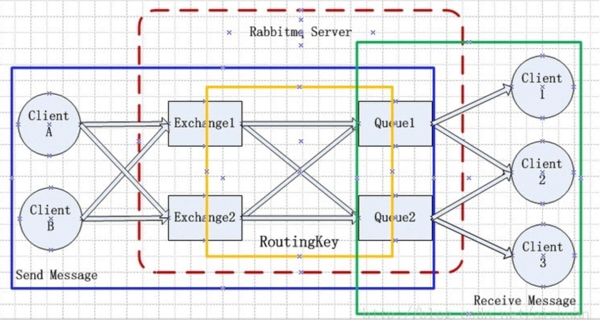
rabbitMQ 路由模型
 kafka 路由模型
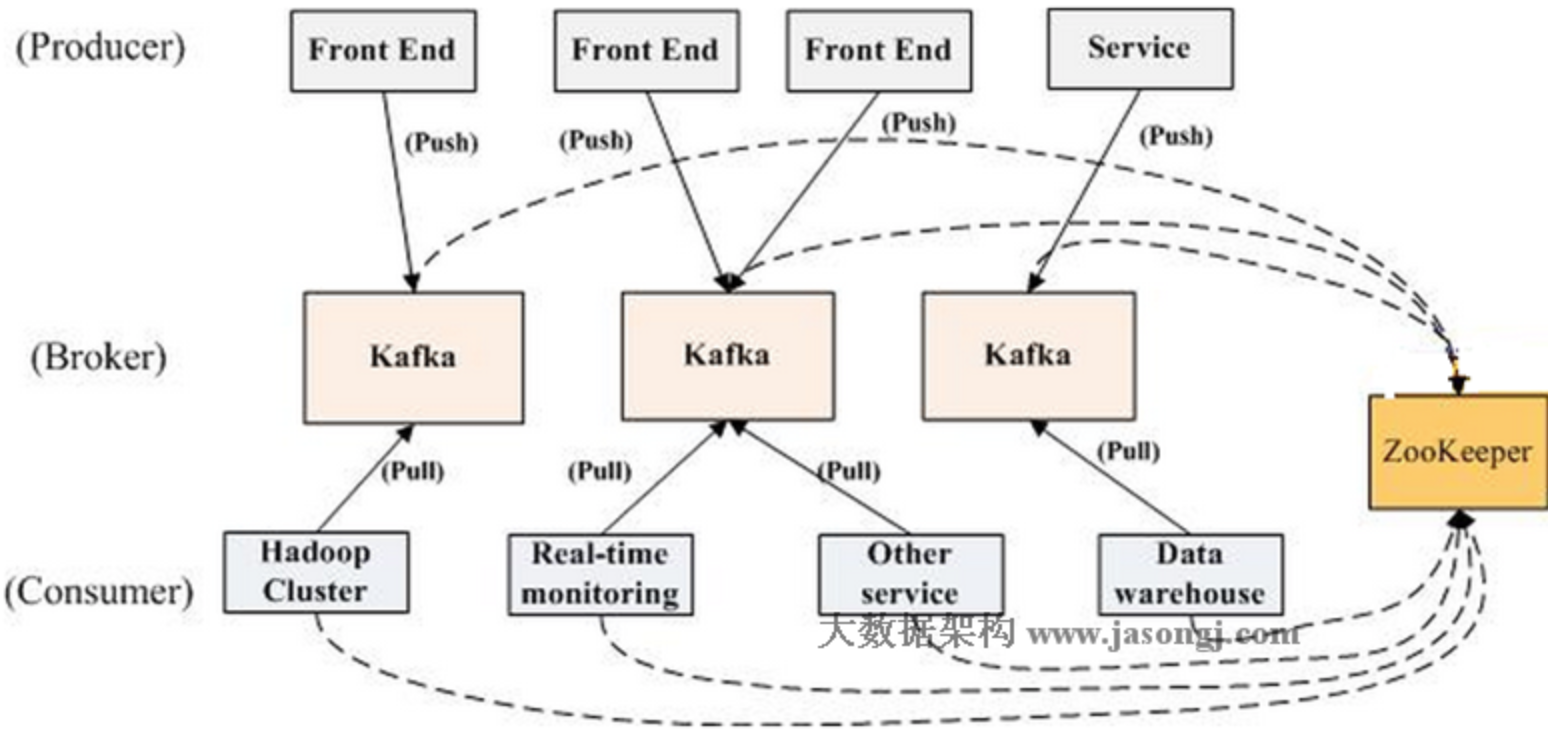
kafka 路由模型
rabbitMQ的路由模型是存储在broker的,发送消息需要关心exchange、queue、routingkey等、消费消息只需要关心自身的队列。绑定关系AMQP协议本身是支持的、可以通过rabbitMQ的管理界面来做。
kafka的绑定和转发关系全部通过zookeeper来存储。
推拉模型
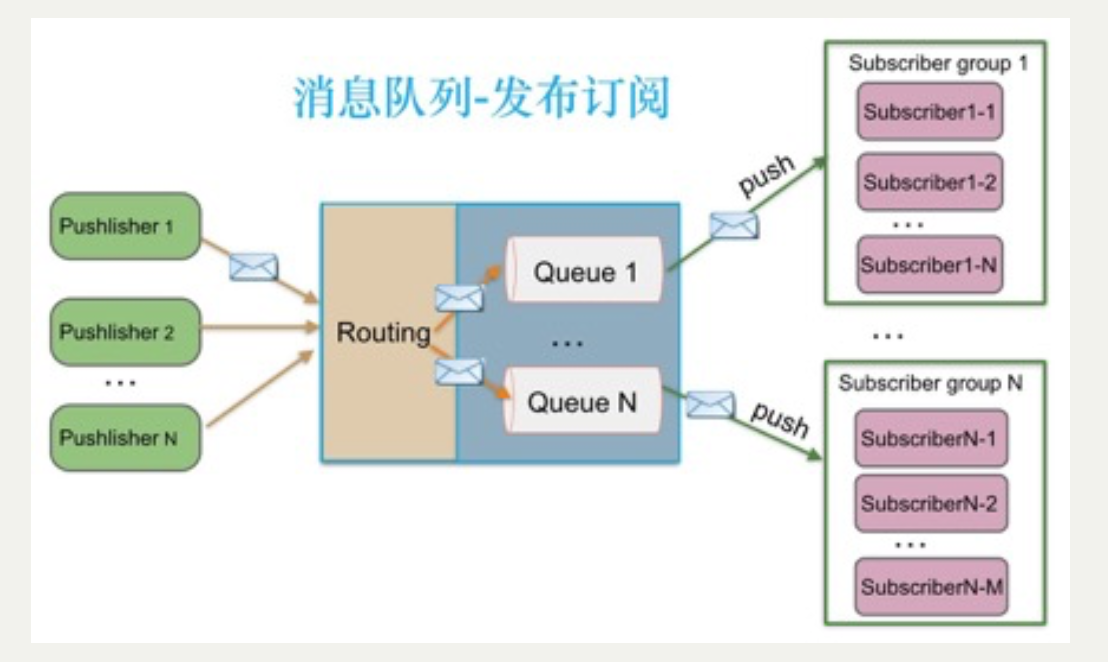
rabbitMQ的模型:
 Kafka模型:
Kafka模型:
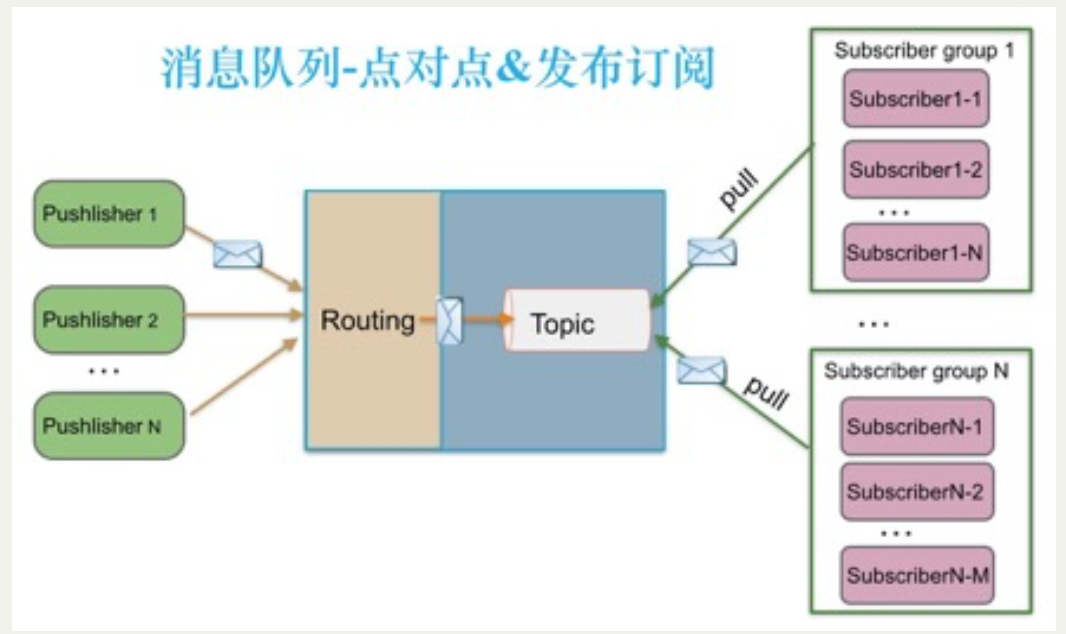
关于推拉模式,主要讲的是的是消费者的部分。rabbitMQ的消费者和broker之间,会建立长连接,broker接收到消息,会推送到消费者进程;而kafka的broker和消费者之间,消费者记录在broker的offset,broker去拉取变更(有点像Mysql主从同步从库拉取binlog变更)。
总体来说,push的模型的变更会第一时间发送到消费者;pull的模型要看消费者pull的频率(具体数据后面补)。对于绝大多数应用而言,对于消费者响应不是特别敏感,无论pull还是push完全能够满足需求,只有在消费者响应特别敏感(ms级别)的应用,这个指标才能作为选型的标准之一。
确认机制
确认机制包括两部分,发送确认和消费确认。
AMQP中,对于发送确认,使用事务机制,但开启事务的性能极低,大约会降低250倍(资料);rabbitMQ为了提升性能,引入了流式的ack机制,相对于事务机制,有较大性能提升,但持久化的消息也至少需要消息写到磁盘,然后发送ack,相对于非持久化消息,也会有10倍左右的性能下降。
对于消费确认,默认情况下,rabbitMQ会把消费失败的消息,丢到下一个消费者消费。对于消费失败的消息会留在队列中。
kafka号称具有以时间复杂度O(1)的方式提供消息持久化的能力,采用顺序IO存储消息(据说顺序IO的性能比随机内存还高),但高可用的消息确认往往通过副本成功(具体细节需要再研究下kafka再说)。
总结
从宏观上看,个人觉得rabbitMQ和kafka最大的区别在:
- RabbitMQ支持AMQP协议,可以和不同的MQ服务互通。
- kafka有较高的吞吐率,性能比RabbitMQ更好。
- RabbitMQ(在节点稳定时)消息可靠度更高。
对于很多业务单位请求量不是很高、可靠度不完全靠MQ来保证(例如考最终一致校验)的应用,两者的选型其实并不重要,重要的是选好型后,把重要特性了解清楚、把方案不足想清楚、把不同部分出问题的预案想好,才能用好。
后续
本文中,对于kafka的部分内容仅限于道听途说的层次,对于rabbitMQ的内容也仅限于官方文档,而没有到代码层面。后续有需呀可以进行更深入的分析。
另外,spring amqp对于rabbitMQ有新一层的抽象,也增加了一些特性,需要进行进一步深入的分析。
参考
- 《rabbitmQ In Action》
- http://www.infoq.com/cn/articles/kafka-analysis-part-1
- https://www.rabbitmq.com/confirms.html
- 本文图片属于盗图,侵权请联系我删除